MaxInfoRL - Boosting exploration in reinforcement learning through information gain maximization
Paper: ICLR 2025.

Abstract
Reinforcement learning (RL) algorithms aim to balance exploiting the current best strategy with exploring new options that could lead to higher rewards. Most common RL algorithms use undirected exploration, i.e., select random sequences of actions. Exploration can also be directed using intrinsic rewards, such as curiosity or model epistemic uncertainty. However, effectively balancing task and intrinsic rewards is challenging and often task-dependent. In this work, we introduce a framework, MaxInfoRL, for balancing intrinsic and extrinsic exploration. MaxInfoRL steers exploration towards informative transitions, by maximizing intrinsic rewards such as the information gain about the underlying task. When combined with Boltzmann exploration, this approach naturally trades off maximization of the value function with that of the entropy over states, rewards, and actions. We show that our approach achieves sublinear regret in the simplified setting of multi-armed bandits. We then apply this general formulation to a variety of off-policy model-free RL methods for continuous state-action spaces, yielding novel algorithms that achieve superior performance across hard exploration problems and complex scenarios such as visual control tasks.
Problem Setting
We study the problem of online reinforcement learning (RL), where the agent interacts with the environment and uses the data collected from these interactions to improve itself.
A core challenge in this setting is deciding whether the agent should leverage its current knowledge to maximize performance or try new actions in pursuit of better solutions. Striking this balance between exploration–exploitation is critical.
Most widely applied online RL algorithms, such as SAC, explore naively. They fail to account for the agent’s lack of knowledge; instead, the agent explores in an undirected fashion by sampling random action sequences. This leads to suboptimal performance, particularly in challenging exploration tasks with continuous state-action spaces. Nonetheless, such algorithms are ubiquitous in RL research due to their simplicity. In this work, we boost these algorithms with directed exploration derived from information gain. Thereby, we maintain the simplicity of the naive exploration methods but obtain better and directed exploration.
MaxInfoRL
We combine Boltzmann exploration based soft-actor critic algorithms (SAC, REDQ, DrQ etc) with intrinsic rewards to obtain principled exploration. In particular, we use an ensemble of forward dynamics model to estimate the information gain of each transition tuple and incorporate it as an exploration bonus in addition to the policy entropy.
This results in the policy update rule described below.
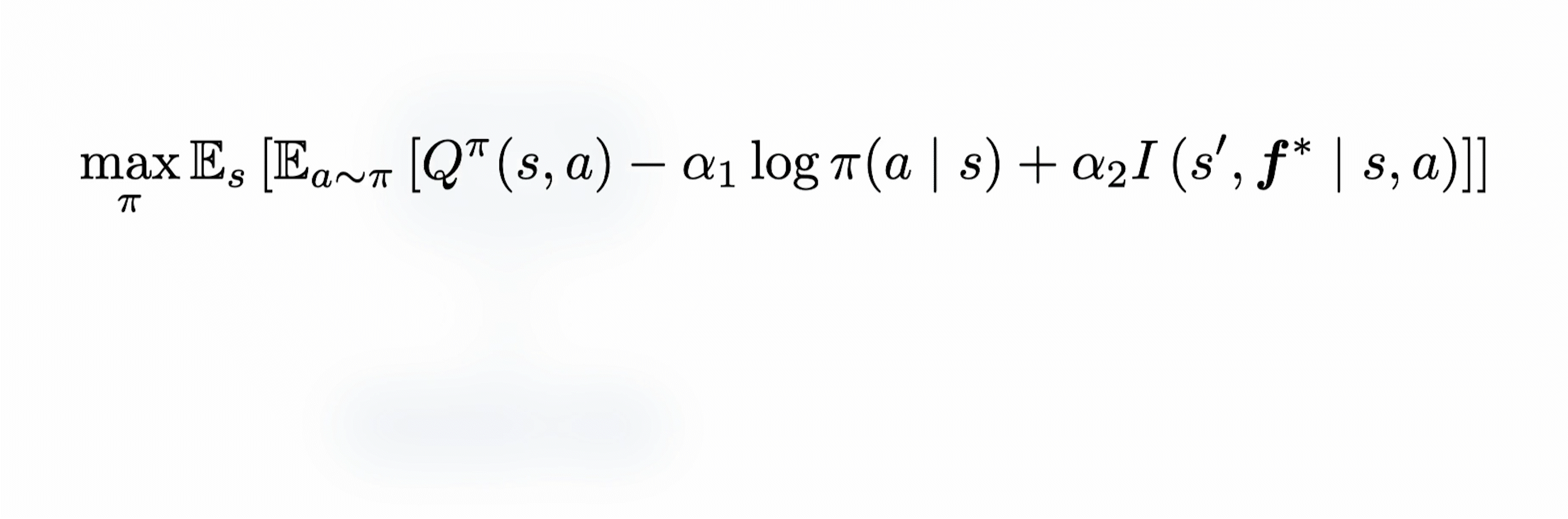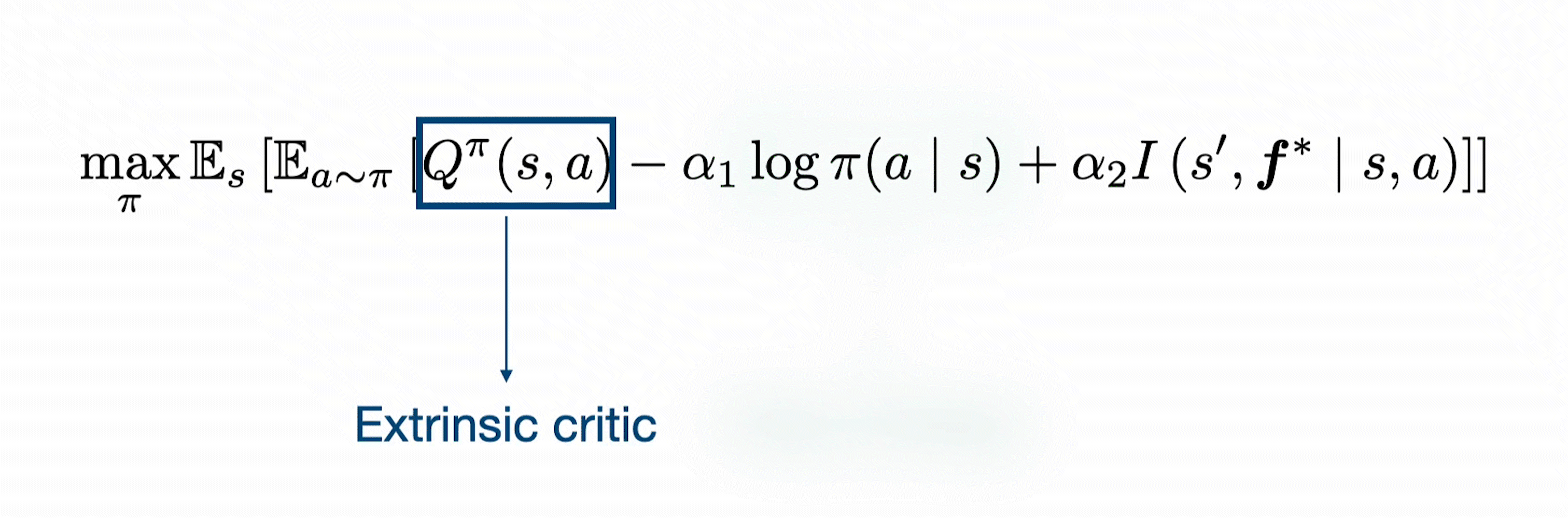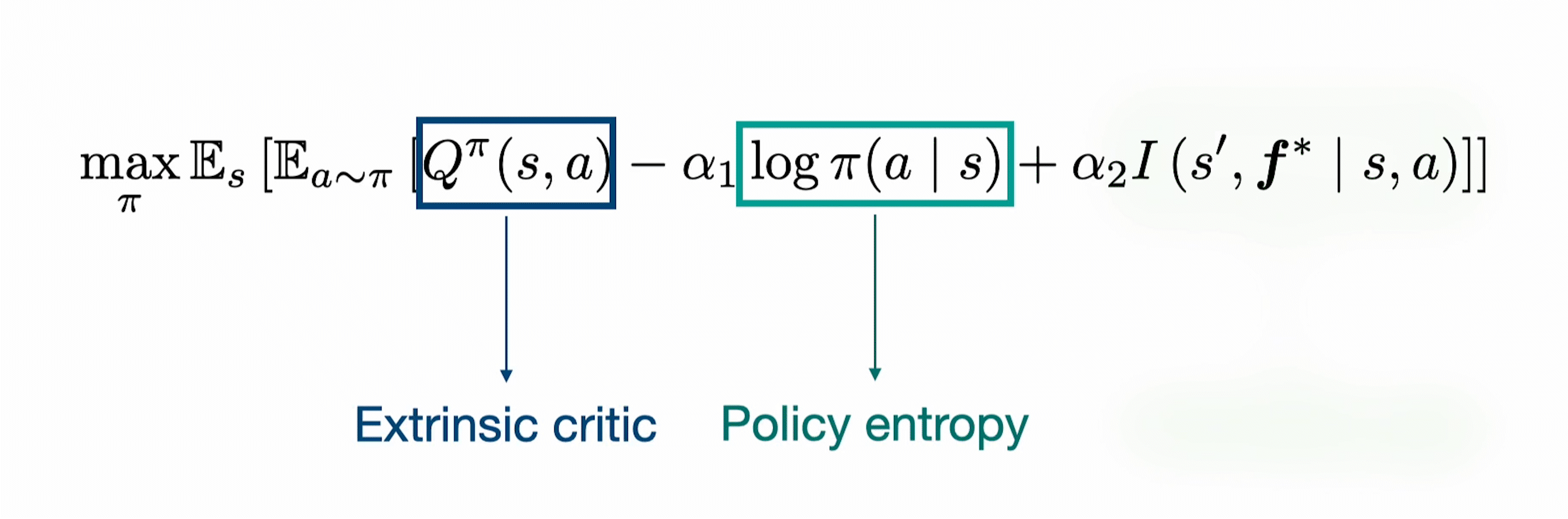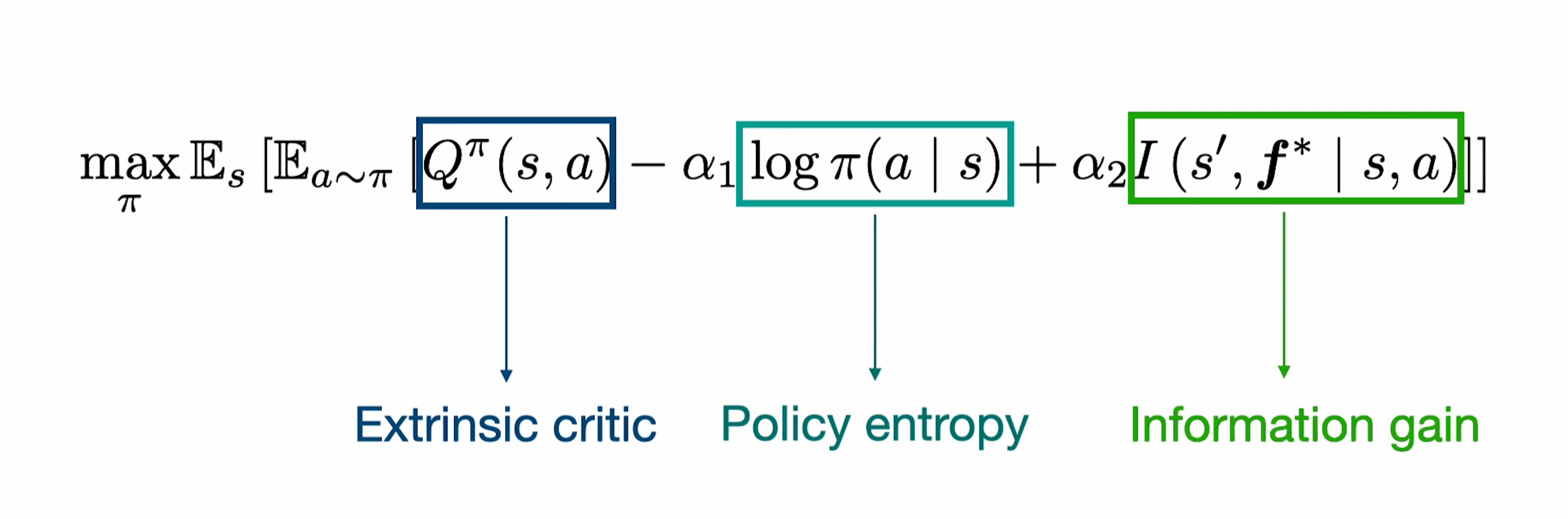
The temperatures $(\alpha_1, \alpha_2)$ are automatically tuned as typically done for soft actor-critic algorithms.
MaxInfoRL maximizes state entropy
While the standard Boltzmann exploration focuses only on the entropy of actions, due to the introduction of the information gain, MaxInfoRL also maximizes the state entropy. This is depcited in the simple graphic below. Where we illustrate on the example of a pendulum that MaxInfoRL covers the state space much more.
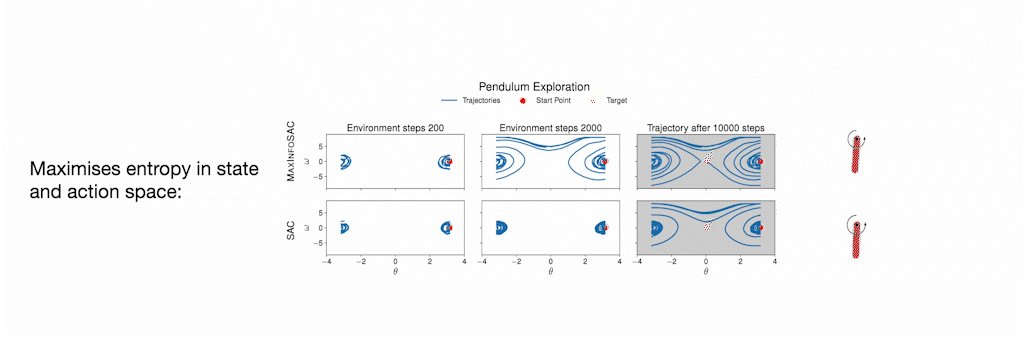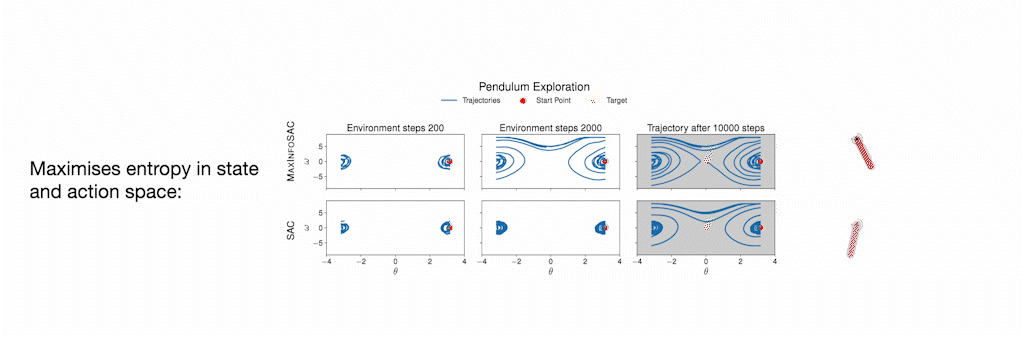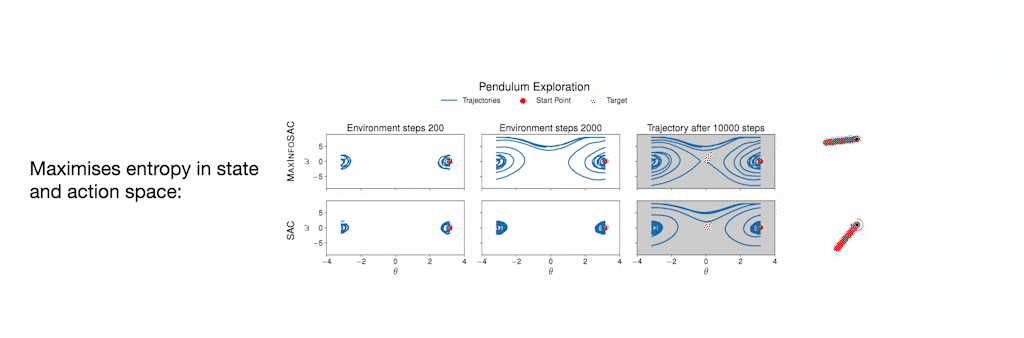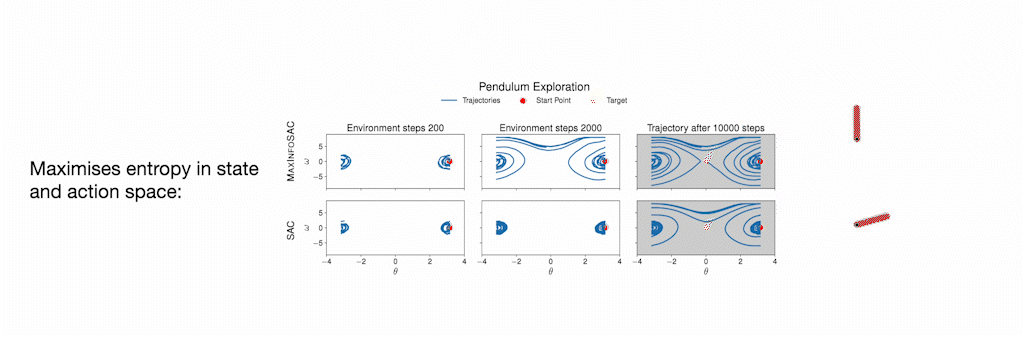
Experiments
MaxInfoRL is flexible!
MaxInfoRL can be combined with different RL algorithms and intrinsic rewards. To illustrate this, we combine it with SAC, REDQ, DrQ, and DrQv2. Furthermore, we also evaluate MaxInfoRL with RND as intrinsic reward. In all cases, the algorithm automatically trades-off extrinsic rewards with intrinsic exploration and outperforms the base algorithm.
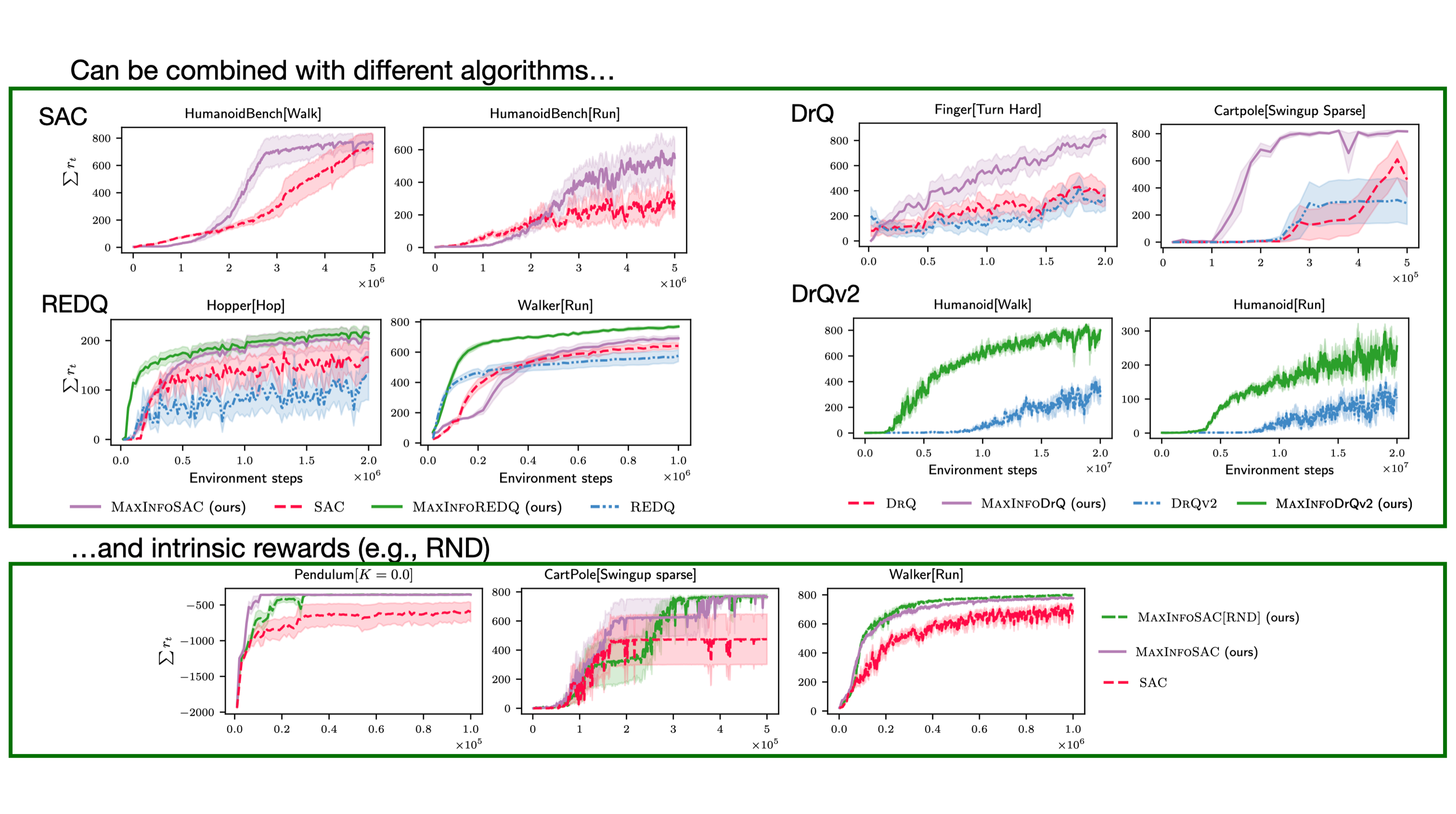
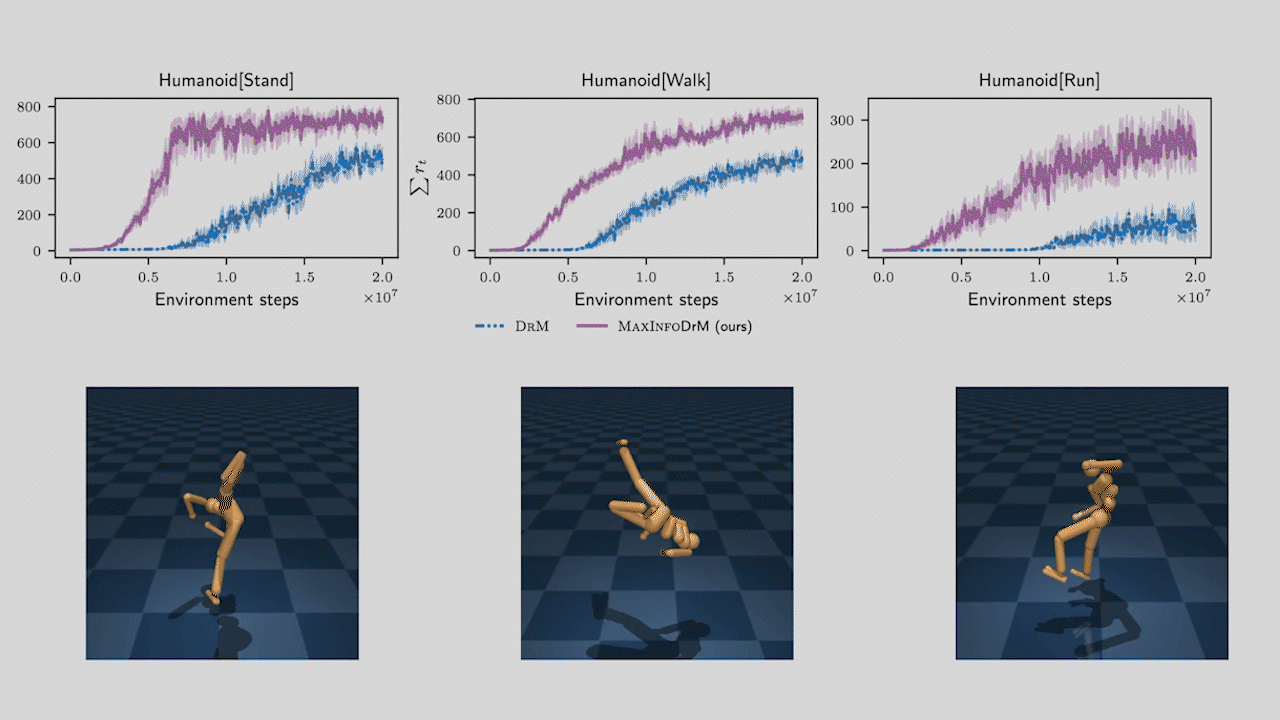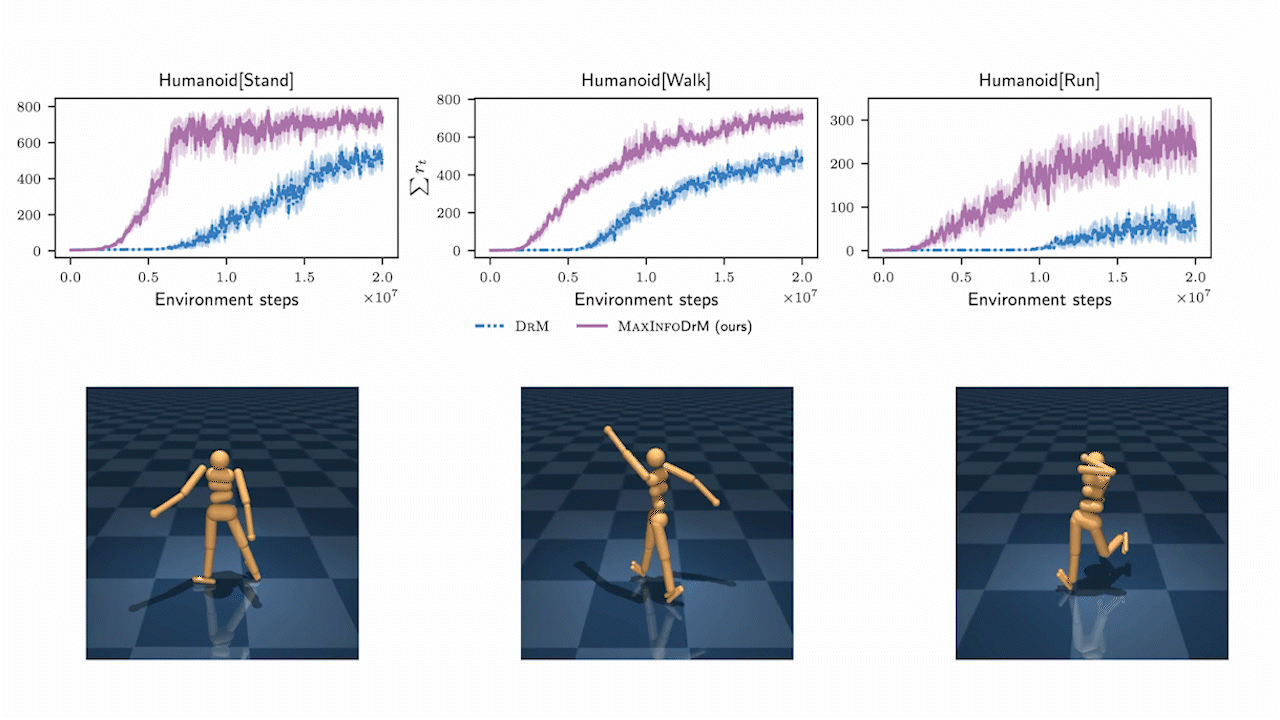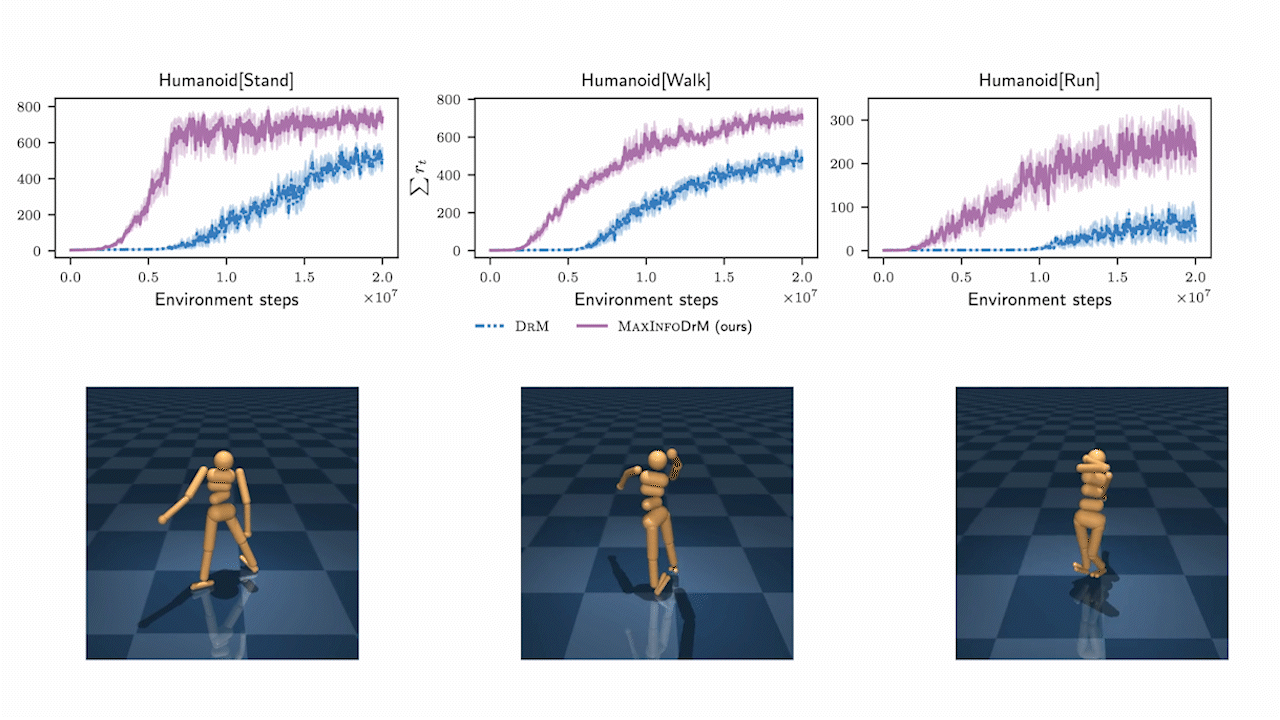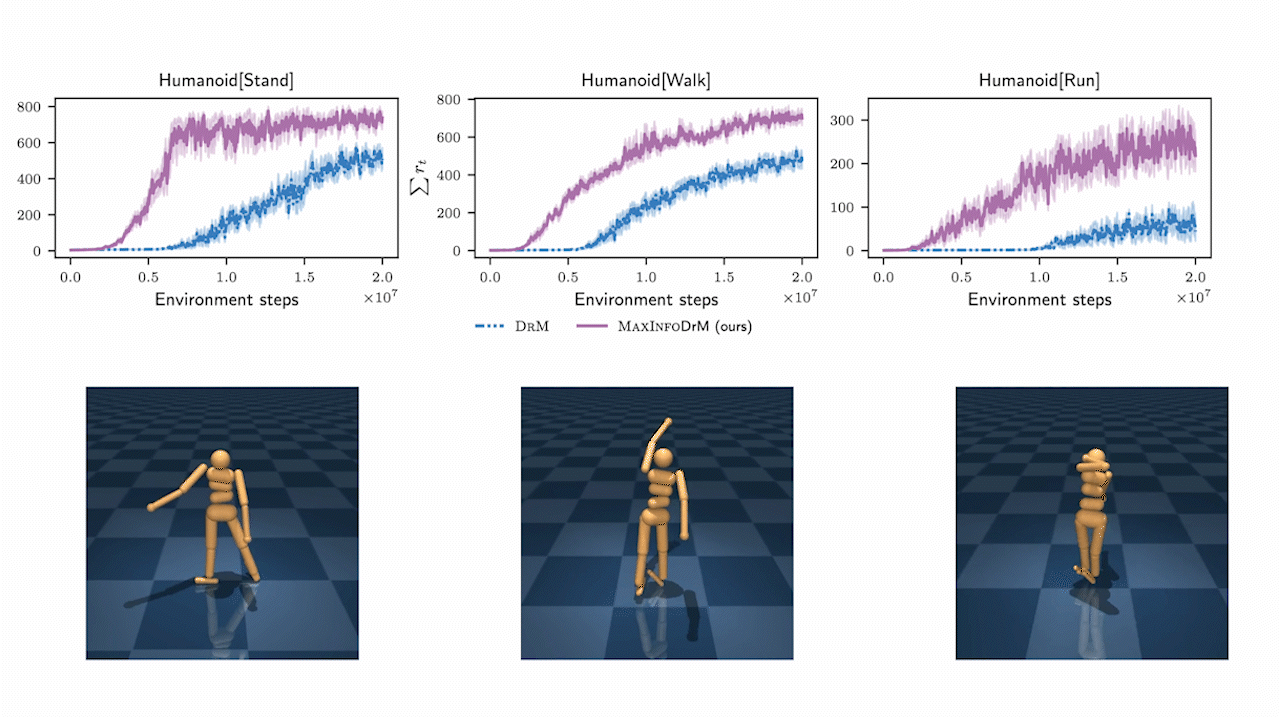
MaxInfoRL is SOTA on hard visual control tasks!
We evaluate MaxInfoRL on hard visual control tasks from the deepmind control suite and show that it outperforms the SOTA: DrM.
Bibtex
@article{sukhija2024maxinforl,
title={MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization},
author={Sukhija, Bhavya and Coros, Stelian and Krause, Andreas and Abbeel, Pieter and Sferrazza, Carmelo},
journal={ICLR},
year={2025}
}