Scalable and Optimistic Model-Based RL maximization
Paper: NeurIPS2025.
Implementation: MBPO
Abstract
We address the challenge of efficient exploration in model-based reinforcement learning (MBRL), where the system dynamics are unknown and the RL agent must learn directly from online interactions. We propose Scalable and Optimistic MBRL (SOMBRL), an approach based on the principle of optimism in the face of uncertainty. SOMBRL learns an uncertainty-aware dynamics model and greedily maximizes a weighted sum of the extrinsic reward and the agent’s epistemic uncertainty. SOMBRL is compatible with any policy optimizers or planners, and under common regularity assumptions on the system, we show that SOMBRL has sublinear regret for nonlinear dynamics in the (i) finite-horizon, (ii) discounted infinite-horizon, and (iii) non-episodic setting. Additionally, SOMBRL offers a flexible and scalable solution for principled exploration. We evaluate SOMBRL on state-based and visual-control environments, where it displays strong performance across all tasks and baselines. We also evaluate SOMBRL on a dynamic RC car hardware and show SOMBRL outperforms the state-of-the-art, illustrating the benefits of principled exploration for MBRL.
Problem Setting
We study the problem of online reinforcement learning (RL), where the agent interacts with the environment and uses the data collected from these interactions to improve itself.
Exploration–Exploitation trade-off plays a crucial role in this setting: Should the agent leverage its current knowledge to maximize performance or try new actions in pursuit of better solutions?
Most widely applied online RL algorithms explore naively and accordingly yield suboptimal performance. On the other hand, principled RL methods, despite their strong theoretical foundations, do not scale to real-world settings and therefore are rarely applied. In this work, we bridge the gap between theory and practice and propose a principled yet scalable algorithm for online RL.
SOMBRL
We combine greedy exploration methods with intrinsic rewards obtained from the epistemic uncertainty of a learned dynamics model. We use an ensemble of forward dynamics model to estimate the model uncertainty of each transition tuple and incorporate it as an exploration bonus. The learned model is then also used for planning yielding additional gains in sample-efficiency. This results in the policy update rule described below.
\[\pi_n = \underset{\pi \in \Pi}{\arg\max}\; \mathbb{E}_{\pi} \left[ \sum^{T-1}_{t=0} r(x'_t, u_t) + \lambda_n ||\sigma_n(x'_t, u_t)|| \right], \; x'_{t+1} = \mu_n(x'_t, u_t) + w_t,\]SOMBRL has sublinear regret for most common RL settings
We theoretically investigate SOMBRL and show that it represents a scalable approach for optimistic exploration in model-based RL. Moreover, we show under regularlity assumptions of the underlying system, that SOMBRL enjoys sublinear regret for the most common RL settings.
Main Theorem: Under regularlity assumptions on the system, SOMBRL has sublinear regret $R_N = \sum^N_{n=1} r_n$ for (i) finite-horizon, (ii) discounted infinite horizon, and (iii) non-episodic average reward settings. Here $r_n$ measures the performance gap between the optimal and current policy.
Experiments
SOMBRL is more scalable than other principled exploration methods!
We compare SOMBRL with other principled exploration algorithms in the episodic HUCRL and nonepisodic setting NeORL. Due to the simplified optimization of SOMBRL, it outperfroms these principled methods and is also computationally cheaper!
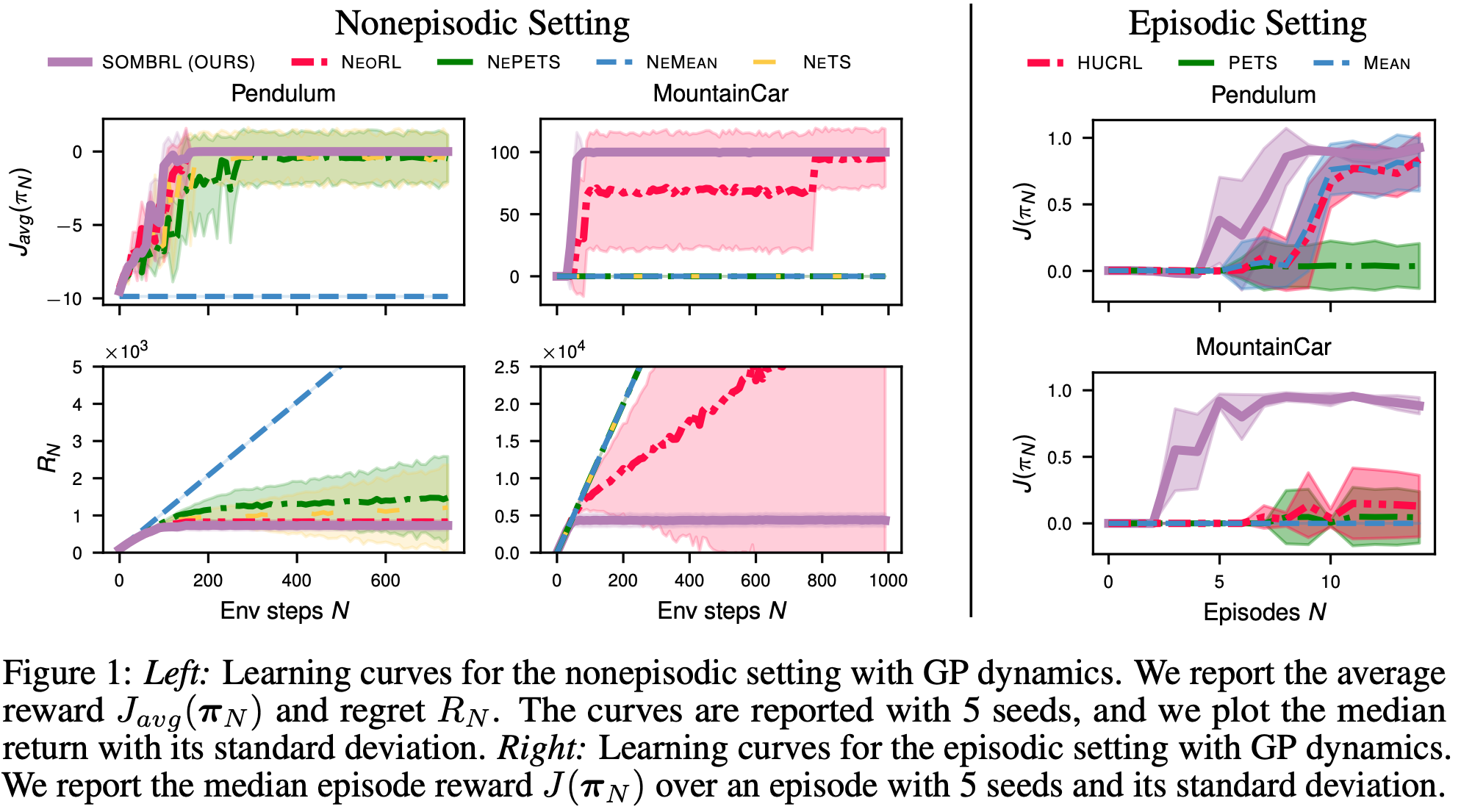
SOMBRL performs well across the board!
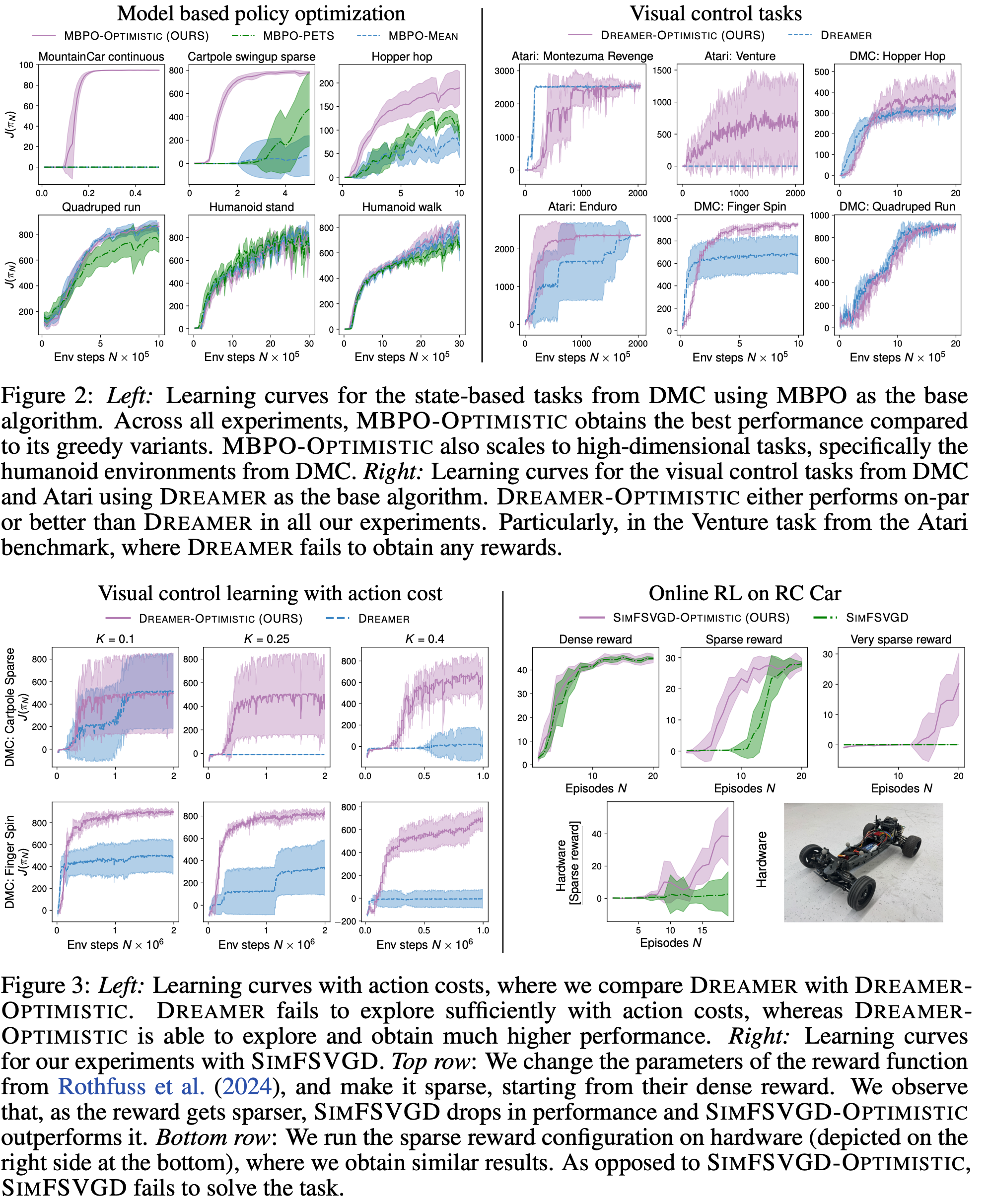
We compare SOMBRL with other deep RL model-based methods on state-based (MBPO) and visual control tasks (Dreamerv3).
Principled exploration methods such as HUCRL, do not scale to these settings.
Whereas scalable methods such as MBPO and Dreamerv3 explore naively, i.e., are not principled.
However, due to SOMBRL’s practical approach to optimistic exploration, it can be seamlessly applied to high-dimensional settings. In addition, SOMBRL is also principled and enjoys theoretical guarantees across several common RL settings. Finally, across all our experiments, SOMBRL performs the best or on-par than the SOTA deep RL baselines, while also having negligible difference in computational cost.
Computational Cost
| Algorithm | Training time |
|---|---|
| HUCRL (GPs) | 90 +/- 3 min (Pendulum), 31.5 +/- 2.5 min (MountainCar) |
| SOMBRL (GPs) | 30 +/- 0.6 min (Pendulum), 13.8 +/- 0.25 min (MountainCar) |
| MBPO-Mean | 9.6 +/- 0.2 min (Time per 100k steps, 1 ensemble, GPU: NVIDIA GeForce RTX 2080 Ti) |
| MBPO-Optimistic | 13.7 +/- 0.35 min (Time per 100k steps, 5 ensembles, GPU: NVIDIA GeForce RTX 2080 Ti) |
| Dreamer | 42.24 +/- 0.95 min (Time per 100k steps, GPU: NVIDIA GeForce RTX 4090) |
| Dreamer-Optimistic | 46.32 +/- 0.34 min (Time per 100k steps, 5 ensembles, GPU: NVIDIA GeForce RTX 4090) |
SOMBRL enables sample-efficient online learning on HW!
We also apply SOMBRL on a real-world HW experiment. Here the task for the agent is to perform a drifting manneuver and park the highly dynamic RC car. The reward for this task is sparse. We compare SOMBRL to the SOTA model-based RL baseline: SimFSVGD. Due to its naive exploration SimFSVGD gets stuck at a local optima whereas SOMBRL finds the optimal solution.

Bibtex
@article{sukhija2025somrbl,
title={SOMBRL: Scalable and Optimistic Model-Based RL},
author={Sukhija, Bhavya and Treven, Lenart and Sferrazza, Carmelo and Dörfler, Florian and Abbeel, Pieter and Krause, Andreas},
journal={NeurIPS},
year={2025}
}